WebArbiter: A Principle-Guided Reasoning Process Reward Model for Web Agents
ICLR 2026
A reasoning-first, principle-inducing WebPRM with structured justifications for step-level web agent supervision.
Why Process Reward Models for Web Agents?
Web interactions involve long-horizon, sequential decision-making with irreversible actions. In such settings, outcome-based supervision is sparse and delayed, often rewarding incorrect trajectories and failing to support inference-time scaling. This motivates the use of Process Reward Models (WebPRMs) for web navigation, but existing approaches remain limited:
Scalar WebPRM
Collapses progress into coarse scores with little interpretability or weak grounding.
Checklist-based WebPRM
Relies on checklists that are brittle under dynamic layouts and state-dependent action semantics, often mislabeling superficially correct actions as successful.
LLM-as-Judge
High cost, limited scalability, susceptible to hallucination, often rewarding fluent but incorrect actions.
Abstract
Web agents hold great potential for automating complex computer tasks, yet their interactions involve long-horizon, sequential decision-making with irreversible actions. In such settings, outcome-based supervision is sparse and delayed, often rewarding incorrect trajectories and failing to support inference-time scaling. This motivates the use of Process Reward Models (WebPRMs) for web navigation, but existing approaches remain limited: scalar WebPRMs collapse progress into coarse, weakly grounded signals, while checklist-based WebPRMs rely on brittle template matching that fails under layout or semantic changes and often mislabels superficially correct actions as successful, providing little insight or interpretability. To address these challenges, we introduce WebArbiter, a reasoning-first, principle-inducing WebPRM that formulates reward modeling as text generation, producing structured justifications that conclude with a preference verdict and identify the action most conducive to task completion under the current context. Training follows a two-stage pipeline: reasoning distillation equips the model with coherent principle-guided reasoning, and reinforcement learning corrects teacher biases by directly aligning verdicts with correctness, enabling stronger generalization. To support systematic evaluation, we release WEBPRMBENCH, a comprehensive benchmark spanning four diverse web environments with rich tasks and high-quality preference annotations. On WEBPRMBENCH, WebArbiter-7B outperforms the strongest baseline, GPT-5, by 9.1 points. In reward-guided trajectory search on WebArena-Lite, it surpasses the best prior WebPRM by up to 6.4 points, underscoring its robustness and practical value in complex web tasks.
Key Contributions
🧠 Reasoning-First WebPRM
We propose WebArbiter, a reasoning-first, principle-inducing PRM trained with reasoning distillation and RL, providing auditable reasoning chains and correctness-aligned signals.
📊 WebPRMBench
We release WebPRMBench, the first comprehensive evaluation benchmark to provide systematic WebPRM evaluation across 4 web environments, using Pairwise and Best-of-N (BoN) Accuracy as standard metrics.
🏆 State-of-the-Art Performance
WebArbiter achieves SOTA on WebPRMBench, surpassing both proprietary LLMs and prior WebPRMs, and delivers up to 6.4-point gains in reward-guided trajectory search on WebArena-Lite.
🔍 Training Design Insights
We analyze the effects of different training components through systematic ablations, showing that cold-start RL alone is unstable across environments, whereas reasoning distillation and explicit principles are essential for stable and transferable progress-aware judgments, with RL primarily acting as an amplifier.
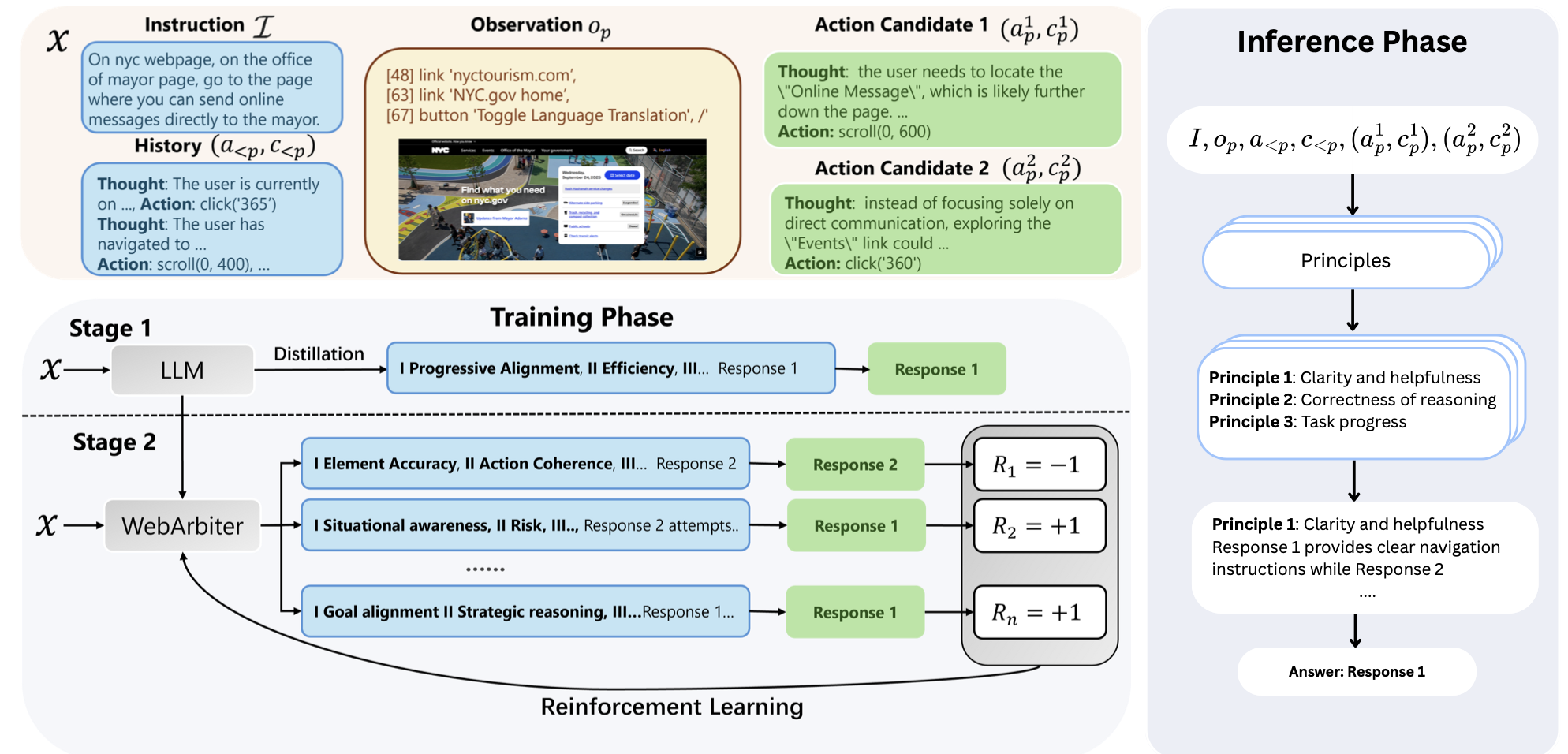
Method Overview
Principle Induction
Dynamically derive evaluation criteria from user intent and current state
Structured Reasoning
Ground each candidate action against principles with auditable reasoning chains
Preference Verdict
Conclude with a verdict identifying the action most conducive to task completion
Two-Stage Training
1 Reasoning Distillation
Distill principle-guided reasoning from a stronger teacher, promoting judgments grounded in explicit principles rather than surface heuristics. Trained via negative log-likelihood on teacher-generated justifications.
2 Reinforcement Learning
Maximize expected reward with KL regularization via GRPO under binary verifiable rewards R ∈ {−1, +1}, correcting teacher biases and enabling cross-environment generalization.
Reward-Guided Trajectory Search
At each decision step, the policy samples 5 candidate actions. WebArbiter runs a knockout tournament—pairwise comparisons grounded in dynamically induced principles—to select the action most conducive to task completion.

5 example trajectories across 5 WebArena-Lite websites · All 72 successful trajectories on HuggingFace COMING SOON
Main Results
On WebPRMBench, WebArbiter-7B achieves the highest Avg. BoN Accuracy, outperforming GPT-5 by 9.1 points and surpassing WebShepherd-8B by an absolute gain of 31 points.
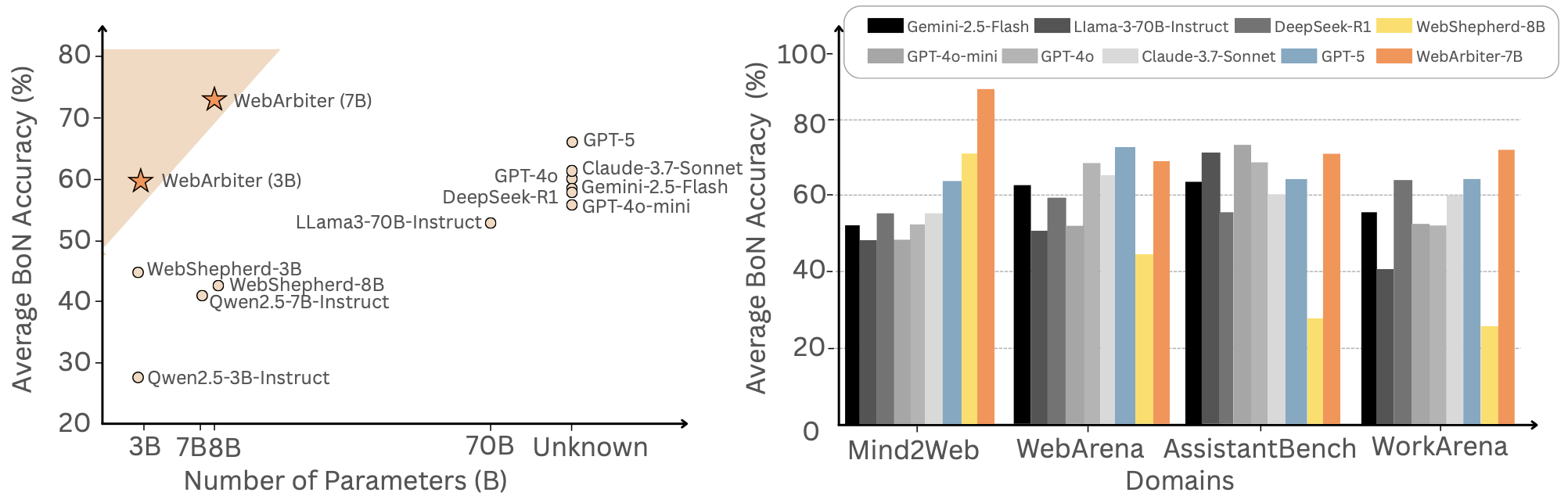
| Model | Mind2Web | WebArena | AssistantBench | WorkArena | Average | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pair. | BoN | Pair. | BoN | Pair. | BoN | Pair. | BoN | Pair. | BoN | |
| LLM-as-Judge, Proprietary | ||||||||||
| GPT-4o-mini | 81.74 | 50.92 | 78.23 | 56.72 | 89.17 | 73.33 | 81.43 | 46.70 | 82.64 | 56.92 |
| GPT-4o | 79.99 | 52.62 | 84.58 | 66.67 | 85.83 | 66.67 | 84.33 | 55.19 | 83.68 | 60.29 |
| GPT-5 | 80.86 | 62.39 | 84.83 | 71.64 | 81.67 | 63.33 | 81.14 | 64.62 | 82.13 | 65.50 |
| Claude-3.7-Sonnet | 80.20 | 57.90 | 82.80 | 64.10 | 81.50 | 61.30 | 82.10 | 60.60 | 81.65 | 60.98 |
| Gemini-2.5-Flash | 81.30 | 57.01 | 82.71 | 62.19 | 80.00 | 63.33 | 83.30 | 56.13 | 81.83 | 59.67 |
| DeepSeek-R1 | 81.62 | 57.37 | 82.04 | 60.21 | 78.49 | 56.18 | 84.12 | 63.89 | 81.57 | 59.41 |
| LLM-as-Judge, Open-Source | ||||||||||
| Qwen2.5-3B-Instruct | 76.46 | 36.93 | 60.32 | 15.42 | 75.83 | 33.33 | 64.45 | 19.34 | 69.27 | 26.76 |
| Qwen2.5-7B-Instruct | 77.79 | 39.18 | 74.88 | 42.79 | 84.17 | 53.33 | 77.58 | 35.85 | 77.61 | 42.78 |
| Llama-3-70B-Instruct | 80.55 | 49.36 | 77.36 | 50.75 | 85.83 | 70.00 | 79.08 | 40.09 | 80.71 | 52.55 |
| WebPRMs (3B) | ||||||||||
| WebShepherd-3B | 87.50 | 65.21 | 68.16 | 41.29 | 66.67 | 46.67 | 50.00 | 21.23 | 68.08 | 43.60 |
| WebArbiter-3B | 93.32 | 78.42 | 81.97 | 56.22 | 78.33 | 46.67 | 81.01 | 54.81 | 83.65 | 59.06 |
| WebPRMs (7B+) | ||||||||||
| WebShepherd-8B | 86.66 | 73.69 | 68.33 | 43.88 | 55.92 | 30.00 | 54.56 | 25.53 | 64.34 | 43.28 |
| WebArbiter-7B | 97.07 | 89.53 | 88.43 | 68.66 | 89.17 | 70.00 | 82.09 | 70.19 | 89.19 | 74.60 |
We evaluate WebArbiter in reward-guided trajectory search on WebArena-Lite, using Best-of-N sampling with a Knockout Tournament mechanism. WebArbiter surpasses WebShepherd by up to 6.4 points, further demonstrating robustness in realistic interaction settings.
| Policy | WebPRM | Shopping | CMS | GitLab | MAP | Avg. | Δ | |
|---|---|---|---|---|---|---|---|---|
| GPT-4o-mini as Policy | ||||||||
| GPT-4o-mini | w/o Trajectory Search* | 21.74 | 22.86 | 19.05 | 34.38 | 19.35 | 23.48 | – |
| GPT-4o-mini | GPT-4o-mini | 24.44 | 22.86 | 26.32 | 33.33 | 15.38 | 24.47 | +0.99 |
| GPT-4o-mini | WebShepherd-8B* | 26.09 | 45.71 | 23.81 | 40.62 | 35.48 | 34.34 | +10.86 |
| GPT-4o-mini | WebArbiter-7B | 37.78 | 42.86 | 36.84 | 46.67 | 38.46 | 40.52 | +17.04 |
| GPT-4o as Policy | ||||||||
| GPT-4o | w/o Trajectory Search* | 23.91 | 31.43 | 28.57 | 56.25 | 19.35 | 31.90 | – |
| GPT-4o | GPT-4o-mini | 26.67 | 37.14 | 42.11 | 40.00 | 19.23 | 33.03 | +1.13 |
| GPT-4o | WebShepherd-8B* | 30.43 | 42.86 | 47.62 | 46.88 | 35.48 | 40.65 | +8.75 |
| GPT-4o | WebArbiter-7B | 44.44 | 42.86 | 52.63 | 56.67 | 38.46 | 47.01 | +15.11 |
Training Design Insights
We compare four training variants to disentangle the effects of RL, principle guidance, and justification style (Table 3).
Cold-Start RL
Instruct + Cold Start RL performs well on in-domain Mind2Web but collapses on out-of-domain benchmarks. Reward optimization without reasoning distillation struggles in noisy and complex environments.
RL + Principle Prompting
Instruct + Cold Start RL + Principles improves both average Pairwise and BoN Acc, especially on AssistantBench and WorkArena, where tasks need context- and state-dependent judgments beyond surface layout cues. Principle-guided reasoning provides transferable criteria for true task progress.
Reasoning w/o Principles + RL
Instruct + SFTw/o Principles + RL uses narrative-style justifications only; fluency improves but performance consistently lags principle-aware settings. Without explicit principles, the model tends to rationalize actions post hoc from surface plausibility and spurious cues.
| Method | Mind2Web | WebArena | AssistantBench | WorkArena | Average | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pair. | BoN | Pair. | BoN | Pair. | BoN | Pair. | BoN | Pair. | BoN | |
| Instruct (Original) | 77.79 | 39.18 | 74.88 | 42.79 | 84.17 | 53.33 | 77.58 | 35.85 | 77.61 | 42.78 |
| Instruct + Cold Start RL | 96.18 | 86.00 | 71.10 | 35.80 | 72.40 | 33.60 | 74.90 | 37.90 | 78.15 | 48.33 |
| Instruct + Cold Start RL + Principles | 96.18 | 88.00 | 77.80 | 46.30 | 80.10 | 48.90 | 82.40 | 51.80 | 84.12 | 58.75 |
| Instruct + SFTw/o Principles + RL | 98.48 | 94.34 | 74.60 | 41.50 | 77.20 | 40.20 | 79.10 | 44.60 | 82.35 | 55.16 |
| WebArbiter-7B | 97.07 | 89.53 | 88.43 | 68.66 | 89.17 | 70.00 | 82.09 | 70.19 | 89.19 | 74.60 |
Reasoning Supervision Analysis
We analyze the role of reasoning supervision by comparing answer-only SFT, distilled reasoning, and RL under both full-data and limited-data (10K) settings (Table 4).
| Method | Mind2Web | WebArena | AssistantBench | WorkArena | Average | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pair. | BoN | Pair. | BoN | Pair. | BoN | Pair. | BoN | Pair. | BoN | |
| Train on Full Data | ||||||||||
| Instruct + SFT | 85.14 | 60.91 | 80.85 | 52.73 | 82.50 | 56.67 | 79.57 | 52.88 | 82.02 | 55.80 |
| Instruct + Distilled + SFT | 87.42 | 61.18 | 81.59 | 52.73 | 83.33 | 63.33 | 81.13 | 56.73 | 83.37 | 58.49 |
| WebArbiter-7B | 97.07 | 89.53 | 88.43 | 68.66 | 89.17 | 70.00 | 82.09 | 70.19 | 89.19 | 74.60 |
| Train on 10K (Stage-1 Reasoning Distillation) Data | ||||||||||
| Instruct + SFT | 84.53 | 60.82 | 82.21 | 58.71 | 82.50 | 56.67 | 80.58 | 39.62 | 82.46 | 53.96 |
| Instruct + Distilled | 85.20 | 63.40 | 83.10 | 61.80 | 83.00 | 60.20 | 81.40 | 55.60 | 83.18 | 60.25 |
Distillation + RL as Amplifier
Reasoning supervision yields more reliable judgments especially under BoN Acc (multi-candidate settings). With full data, answer-only SFT after distillation gives environment-dependent gains because final-answer optimization can reintroduce shortcuts; distillation still grounds judgments in true task progress. RL then enlarges the margin between progress-making and spurious trajectories.
Especially Effective Under Limited Data
Under the 10K (stage-1 distillation) setting, Instruct + Distilled beats Instruct + SFT on both Pairwise and BoN Acc in every environment (e.g. +6.29 Avg. BoN Acc). Identical data budgets imply gains come from biasing the model toward progress-aware reward judgments, not from scale.
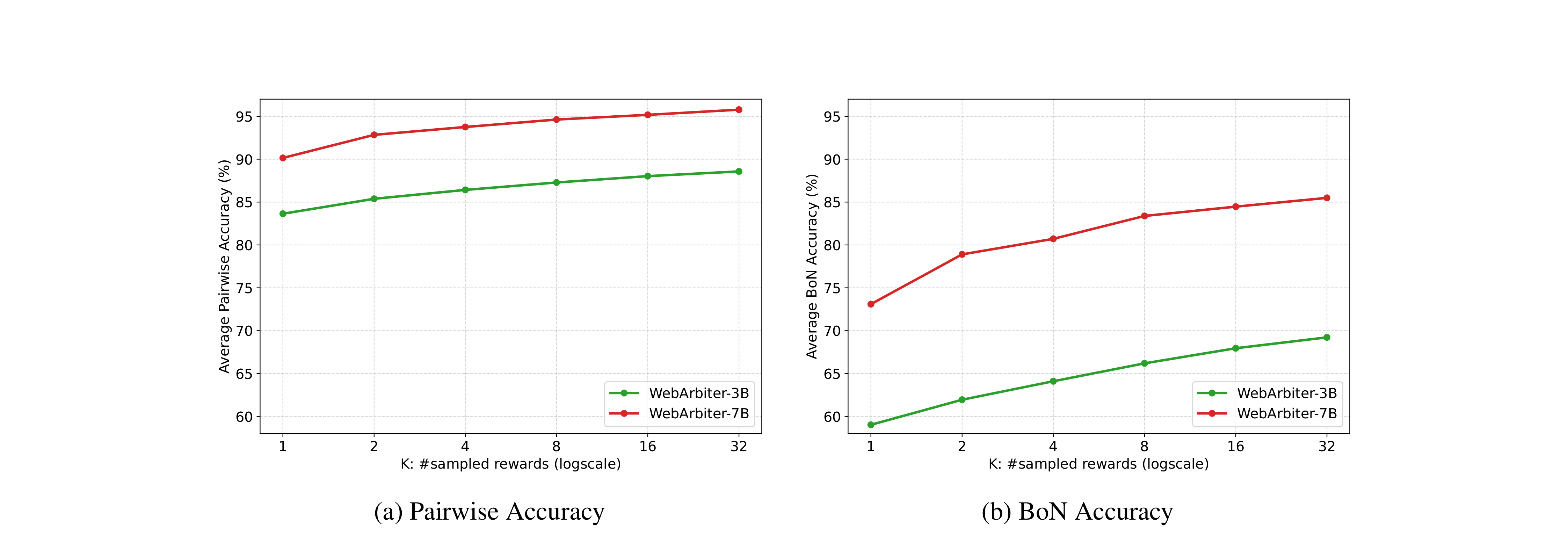
Inference-Time Scaling
As the number of sampled evaluations K increases, both Pairwise and BoN Accuracy improve consistently. Gains are more pronounced under the stricter BoN Acc, highlighting the advantage of additional inference-time compute in multi-distractor ranking.
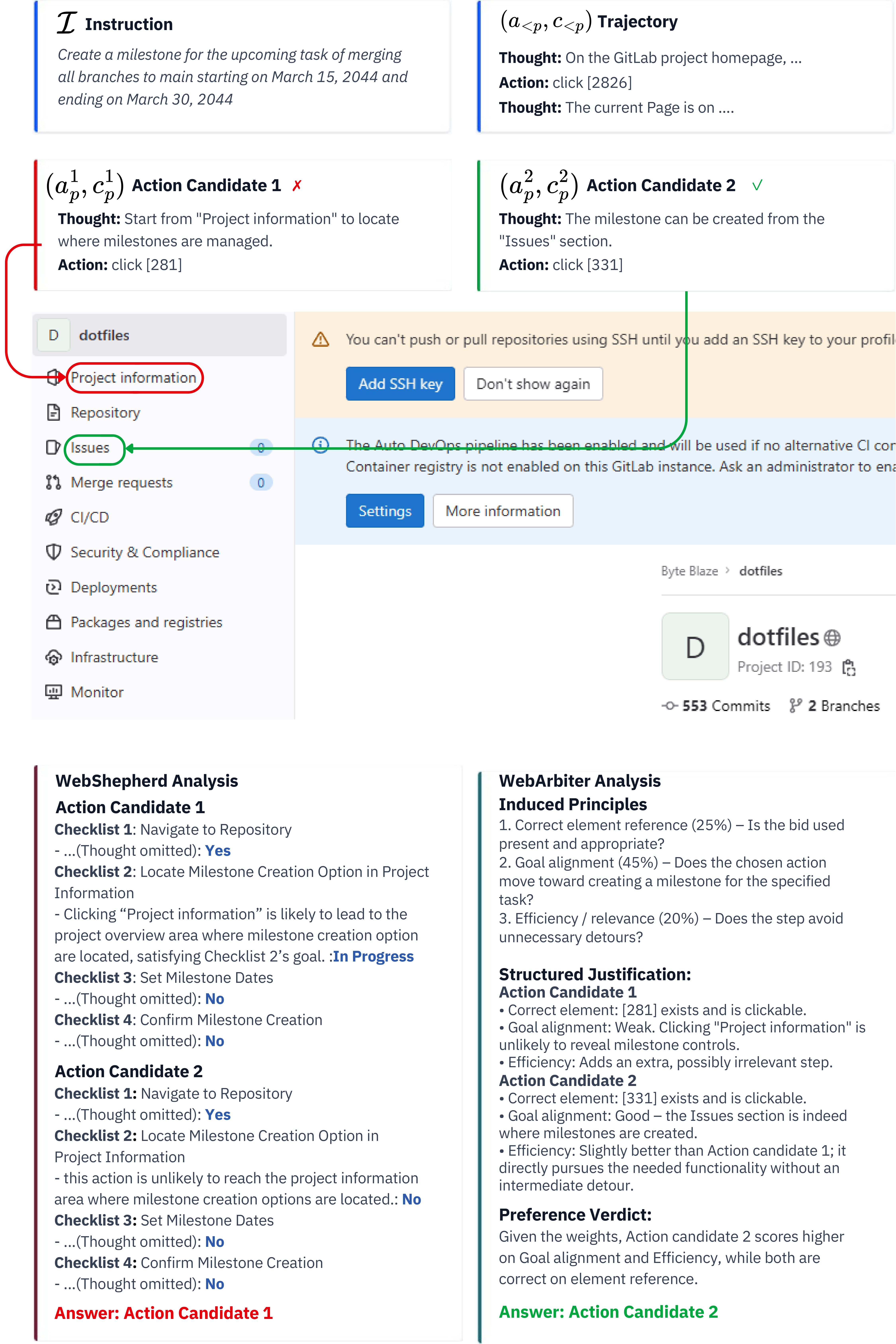
Case Study
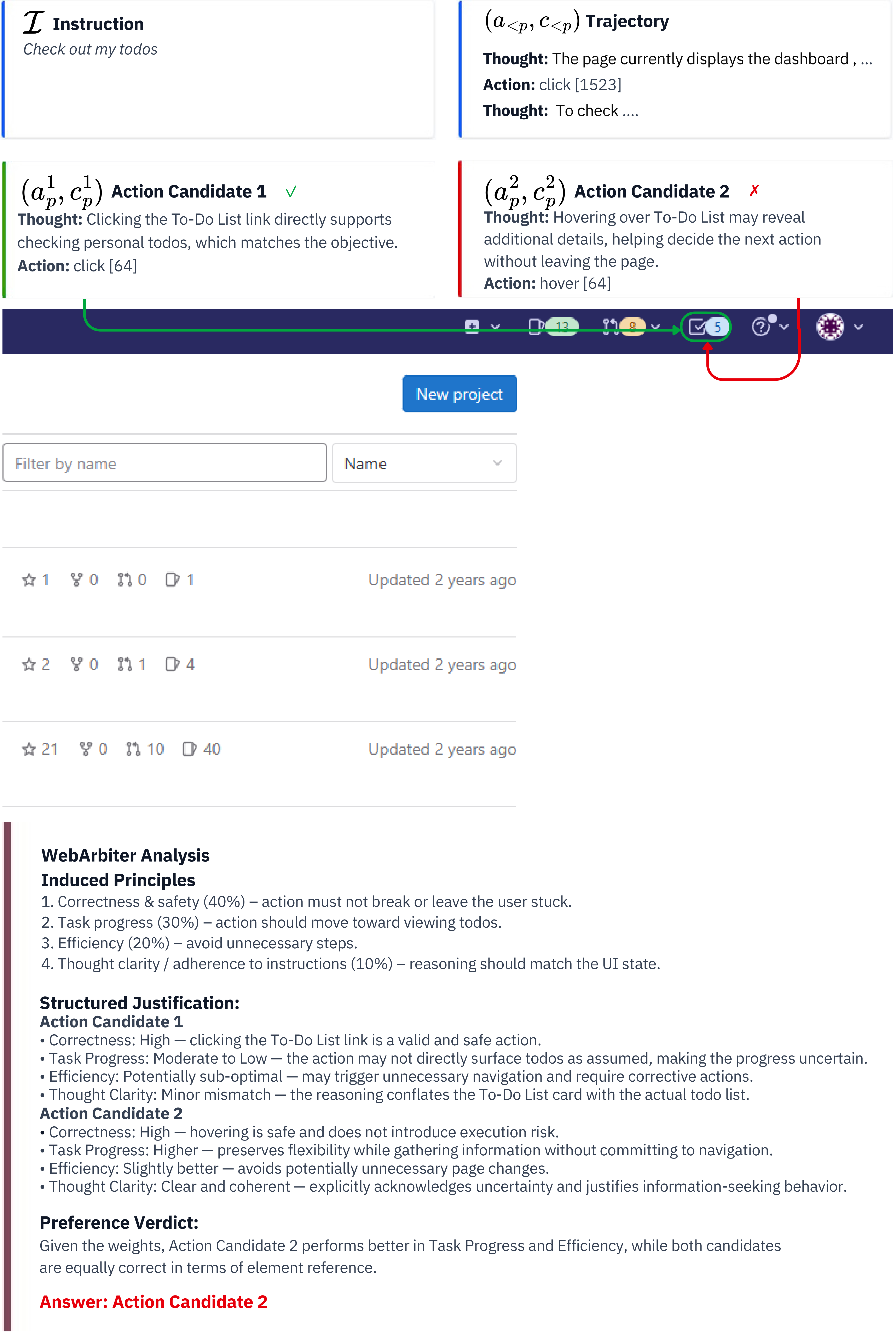
We compare WebArbiter with WebShepherd on real trajectory search examples from WebArena-Lite. WebArbiter's principle-guided reasoning correctly identifies the preferred action, while checklist-based methods are misled by surface-level cues.
Hover to zoom & pan · Scroll to navigate vertically · Click for full PDF
Failure Cases
We examine two recurring failure patterns on GitLab, revealing open challenges for text-based WebPRMs that rely on accessibility-tree observations.
Hover to zoom & pan · Scroll to navigate vertically · Click for full PDF
WebPRMBench
We introduce WebPRMBench, the first comprehensive evaluation benchmark for evaluating WebPRMs. It provides 1,150 step-level preference instances, each consisting of one correct action and four rejected alternatives, collected across 4 web environments.
BibTeX
@misc{zhang2026webarbiterprincipleguidedreasoningprocess,
title={WebArbiter: A Principle-Guided Reasoning Process Reward Model for Web Agents},
author={Yao Zhang and Shijie Tang and Zeyu Li and Zhen Han and Volker Tresp},
year={2026},
eprint={2601.21872},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2601.21872},
}